
Hi, I am Hongyang Du — a Sc.M. student in Computer Science at
Brown University advised by
Randall Balestriero. Currently I am
collaborating with Yue Wang at the
USC Physical SuperIntelligence Lab.
I previously obtained my B.S. in Computer Science and Mathematics from the
University of Maryland, College Park.
My research explores how Self-Supervised Learning can build World Models for Robotic Control. I focus on extracting spatiotemporal and 3D-aware priors to capture physical dynamics and how to create a scalable loop that couples causal prediction and action prediction.
Outside of research, I am an amateur powerlifter 💪 and a pro drummer 🥁; I am a Jazz cat and prog metalhead — think Chick Corea meets Animals as Leaders. Also, I live with a cat named Dingzhen(丁真)🐱, who keeps me grounded.
Action required
Problem: The current root path of this site is "baseurl ("_config.yml.
Solution: Please set the
baseurl in _config.yml to "Education
-
 Brown UniversityDepartment of Computer Science
Brown UniversityDepartment of Computer Science
Master's StudentAug. 2025 - present -
 University of Maryland, College ParkB.S. in Computer Science and MathematicsAug. 2021 - May. 2025
University of Maryland, College ParkB.S. in Computer Science and MathematicsAug. 2021 - May. 2025
Honors & Awards
-
Robert Ma Scholarship Recipent2024
-
Break Thhrough Tech Scholarship Recipent2021
News
VideoGPA won 🥉 place in Image-to-Video Consistent Generation Challenge!Self-Evolving Agentic Image Gen!VideoGPA accepted to ICML 2026!Video INR Compression accepted to WACV 2026!VideoHallu accepted to NeurIPS 2025!Brown University in Fall 2025University of Maryland, College Park with Bachelor’s in Computer Science (Honors) and Minor in Mathematics!VLM Survey accepted to CVPR Workshop 2025 as Oral presentation!Agriculture MLLM Team.Selected Publications (view all )
Vision & Geometric Representation
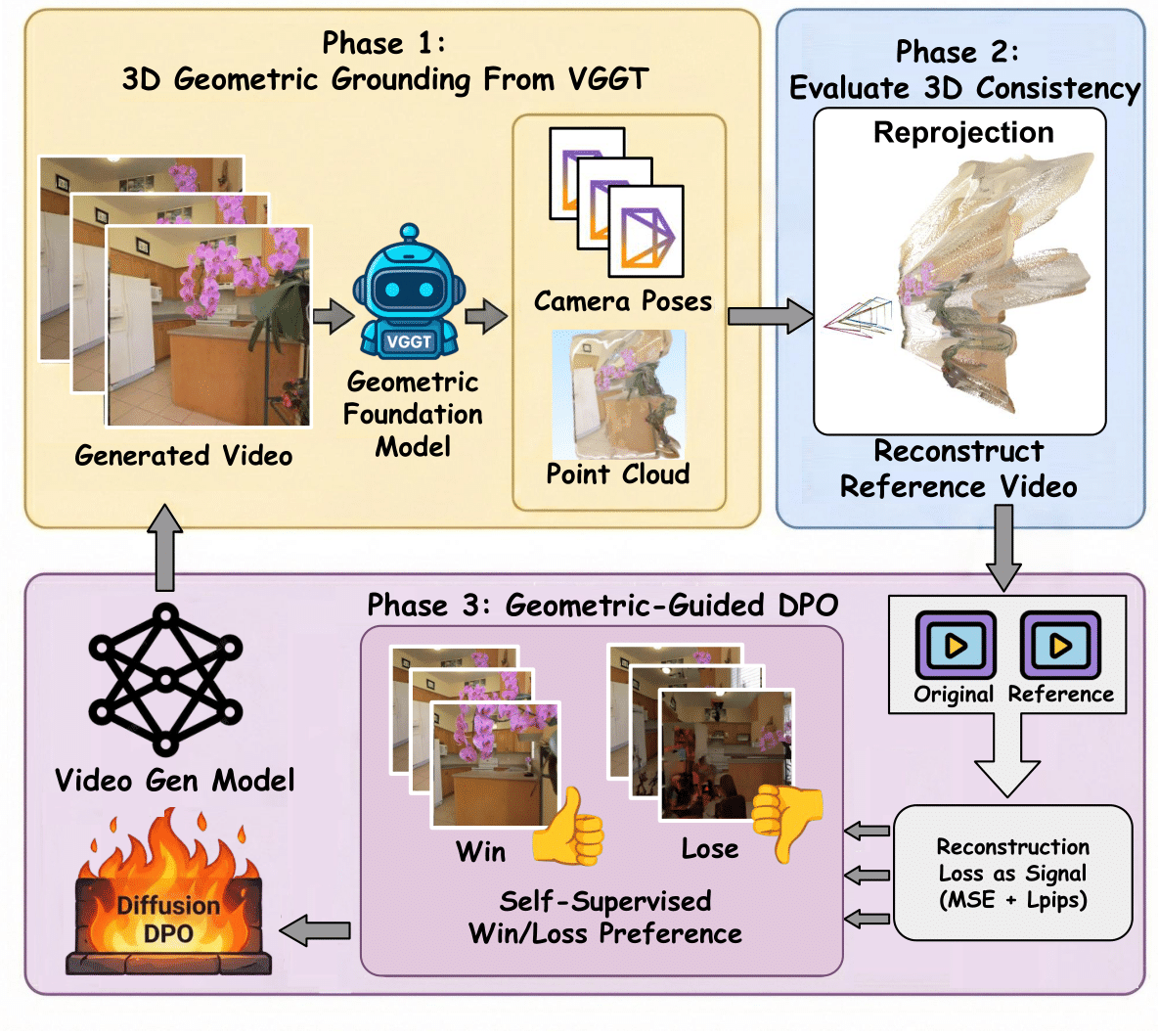
VideoGPA: Distilling Geometry Priors for 3D-Consistent Video Generation
Hongyang Du*, Junjie Ye*, Xiaoyan Cong*, Runhao Li, Jingcheng Ni, Aman Agarwal, Zeqi Zhou, Zekun Li, Randall Balestriero, Yue Wang (* equal contribution)
ICML 2026, CVPR Workshop 2026 Oral
TL;DR: VideoGPA uses a geometry foundation model to mine preference pairs for DPO, nudging video diffusion toward 3D-consistent motion without hand-labeled human preferences. CVPR VGBE Challenge 🥉
VideoGPA: Distilling Geometry Priors for 3D-Consistent Video Generation
Hongyang Du*, Junjie Ye*, Xiaoyan Cong*, Runhao Li, Jingcheng Ni, Aman Agarwal, Zeqi Zhou, Zekun Li, Randall Balestriero, Yue Wang (* equal contribution)
ICML 2026, CVPR Workshop 2026 Oral
TL;DR: VideoGPA uses a geometry foundation model to mine preference pairs for DPO, nudging video diffusion toward 3D-consistent motion without hand-labeled human preferences. CVPR VGBE Challenge 🥉
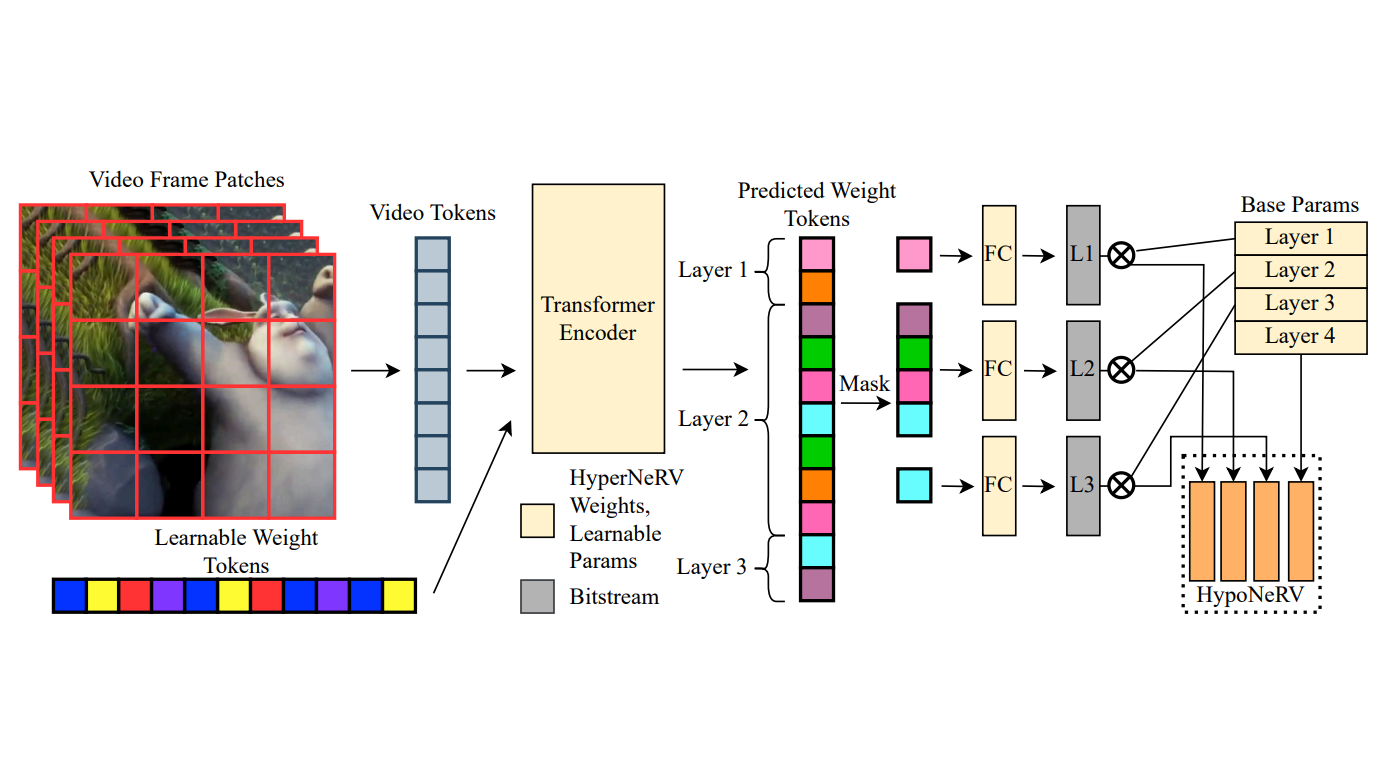
How to Design and Train Your Implicit Neural Representation for Video Compression
Matthew Gwilliam, Roy Zhang, Namitha Padmanabhan, Hongyang Du, Abhinav Shrivastava
WACV 2026
TL;DR: We dissect NeRV-style video INRs in a library, propose Rabbit NeRV (RNeRV) as a strong recipe under equal training budget, then use hyper-networks + weight masking to speed encoding while keeping quality competitive.
How to Design and Train Your Implicit Neural Representation for Video Compression
Matthew Gwilliam, Roy Zhang, Namitha Padmanabhan, Hongyang Du, Abhinav Shrivastava
WACV 2026
TL;DR: We dissect NeRV-style video INRs in a library, propose Rabbit NeRV (RNeRV) as a strong recipe under equal training budget, then use hyper-networks + weight masking to speed encoding while keeping quality competitive.
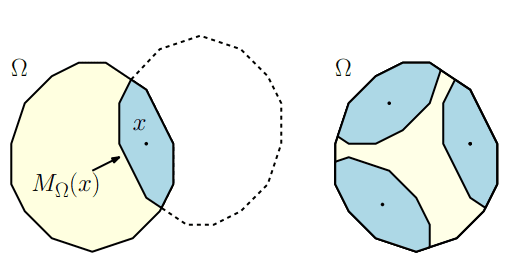
Ipelets for the Convex Polygonal Geometry
Nithin Parepally, Ainesh Chatterjee, Auguste Gezalyan, Hongyang Du, Sukrit Mangla, Kenny Wu, Sarah Hwang, David Mount
40th International Symposium on Computational Geometry (SoCG) 2024
TL;DR: New Ipelets for the Ipe editor that draw and explore convex polygonal geometry—Funk/Hilbert metric balls, polar bodies, enclosing balls, MSTs, and polygon utilities (union, intersection, Minkowski sum).
Ipelets for the Convex Polygonal Geometry
Nithin Parepally, Ainesh Chatterjee, Auguste Gezalyan, Hongyang Du, Sukrit Mangla, Kenny Wu, Sarah Hwang, David Mount
40th International Symposium on Computational Geometry (SoCG) 2024
TL;DR: New Ipelets for the Ipe editor that draw and explore convex polygonal geometry—Funk/Hilbert metric balls, polar bodies, enclosing balls, MSTs, and polygon utilities (union, intersection, Minkowski sum).
VLMs & Agents
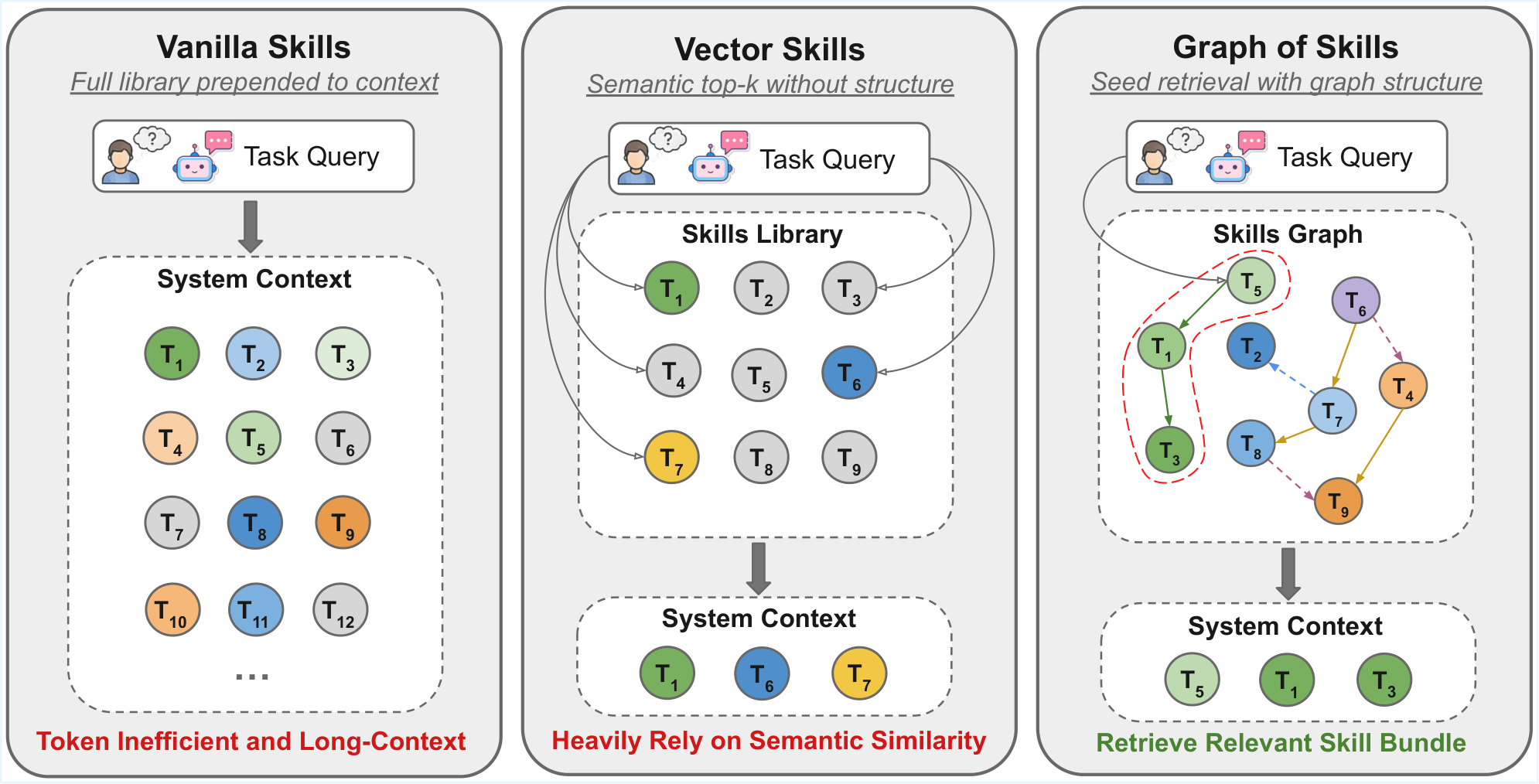
Graph of Skills: Dependency-Aware Structural Retrieval for Massive Agent Skills
Dawei Liu*, Zongxia Li*, Hongyang Du, Xiyang Wu, Shihang Gui, Yongbei Kuang, Lichao Sun (* equal contribution)
ACM CAIS Workshop 2026
TL;DR: Graph of Skills (GoS): offline skill dependency graph + inference-time retrieval (seeding + PageRank + token budget) so agents load a small, relevant skill bundle instead of the whole library—higher reward, fewer tokens.
Graph of Skills: Dependency-Aware Structural Retrieval for Massive Agent Skills
Dawei Liu*, Zongxia Li*, Hongyang Du, Xiyang Wu, Shihang Gui, Yongbei Kuang, Lichao Sun (* equal contribution)
ACM CAIS Workshop 2026
TL;DR: Graph of Skills (GoS): offline skill dependency graph + inference-time retrieval (seeding + PageRank + token budget) so agents load a small, relevant skill bundle instead of the whole library—higher reward, fewer tokens.

MM-Zero: Self-Evolving Multi-Model Vision Language Models From Zero Data
Zongxia Li*, Hongyang Du*, Chengsong Huang*, Xiyang Wu, Lantao Yu, Yicheng He, Jing Xie, Xiaomin Wu, Zhichao Liu, Jiarui Zhang, Fuxiao Liu (* equal contribution)
Preprint 2026
TL;DR: MM-Zero trains one base VLM in three roles—Proposer, Coder (code-to-image), Solver—with GRPO and rich rewards, achieving self-evolution on multimodal reasoning without any seed images.
MM-Zero: Self-Evolving Multi-Model Vision Language Models From Zero Data
Zongxia Li*, Hongyang Du*, Chengsong Huang*, Xiyang Wu, Lantao Yu, Yicheng He, Jing Xie, Xiaomin Wu, Zhichao Liu, Jiarui Zhang, Fuxiao Liu (* equal contribution)
Preprint 2026
TL;DR: MM-Zero trains one base VLM in three roles—Proposer, Coder (code-to-image), Solver—with GRPO and rich rewards, achieving self-evolution on multimodal reasoning without any seed images.

VideoHallu: Evaluating and Mitigating Multi-modal Hallucinations for Synthetic Videos
Zongxia Li*, Xiyang Wu*, Yubin Qin, Hongyang Du, Guangyao Shi, Dinesh Manocha, Tianyi Zhou, Jordan Lee Boyd-Graber (* equal contribution)
NeurIPS 2025
TL;DR: VideoHallu: benchmark of synthetic videos (e.g. from frontier generators) with QA that exposes commonsense and physics failures; we show strong MLLMs still struggle and that GRPO fine-tuning (with counterexamples) helps.
VideoHallu: Evaluating and Mitigating Multi-modal Hallucinations for Synthetic Videos
Zongxia Li*, Xiyang Wu*, Yubin Qin, Hongyang Du, Guangyao Shi, Dinesh Manocha, Tianyi Zhou, Jordan Lee Boyd-Graber (* equal contribution)
NeurIPS 2025
TL;DR: VideoHallu: benchmark of synthetic videos (e.g. from frontier generators) with QA that exposes commonsense and physics failures; we show strong MLLMs still struggle and that GRPO fine-tuning (with counterexamples) helps.